
Paper Collection, November '23
Unlearnability, efficient debate, GPQA, analyzing RLHF, finetuning as "wrappers", LLM persuasiveness, GPT-4 in the Turing test

tl;dr
2 papers on “unlearnability” show how to prevent models from learning certain concepts by manipulating gradients or by making models indifferent.
Other highlights include scalable oversight via efficient debate, the GPQA benchmark for testing scalable oversight, analyzing RLHF with sparse autoencoders (yes, already!), RLHF finetuning apparently only creating “wrappers”, evidence for systematic LLM persuasiveness, and GPT-4 in the Turing test.
⭐Papers of the month⭐
Making Harmful Behaviors Unlearnable and Removing NSFW Concepts
Making Harmful Behaviors Unlearnable for Large Language Models [Fudan] and Removing NSFW Concepts from Vision-and-Language Models for Text-to-Image Retrieval and Generation [Modena]
“Unlearnability” is an area of research that aims at preventing models from learning certain concepts or outputs. It’s already an active area of research in image models, and is now expanding to LLMs. Note that “unlearnability” is different to “unlearning”, which aims to remove concepts after the fact.
This area is highly relevant to the safety of advanced AI: If we can prevent problematic behavior, like deception or power seeking, we step closer to beneficial advanced AI.
Note in particular unlearnability’s close relationship to “utility indifference”, which also aims at preventing problematic behavior – in this case typically to prevent shutdown obstruction.
To achieve unlearnability, Making Harmful Behaviors Unlearnable for Large Language Models adds “security vectors” to LLM activations. Counter-intuitively, these vectors cause the model to generate harmful responses during training. The trick is that these vectors thus become the cause of harmful outputs, and training only changes these vectors, not the model itself. Thus, they prevent the model from learning harmful responses.
Removing NSFW Concepts from Vision-and-Language Models for Text-to-Image Retrieval and Generation starts with a pre-trained vision-and-language model. The authors then make the model indifferent to not-safe-for-work (NSFW) content by training a new text encoder whose output embeddings have high similarity with the original text encoder’s embedding of safe text, irrespective of whether the text is safe or unsafe.
[⭐ = Editor’s choice]
High-level analysis and surveys
The Alignment Problem in Context [Macquarie] connects the adversarial vulnerability and misalignment of LLMs to their in-context learning ability. It concludes that robust alignment would undermine central in-context learning capabilities. As a result, alignment would be intrinsically difficult, for both current and future LLMs.
Explainability for Large Language Models: A Survey [NJIT] provides an overview of methods for explaining transformer-based language models.
Scalable oversight
⭐ Scalable AI Safety via Doubly-Efficient Debate [Google DeepMind] designs debate protocols where the honest strategy can succeed using a simulation of a polynomial number of steps and can verify the alignment of stochastic AI systems. This makes progress on the original “AI safety via debate” proposal, which needed deterministic AI systems and an exponential number of steps.
⭐ GPQA: A Graduate-Level Google-Proof Q&A Benchmark [NYU] contains difficult multiple-choice questions that are “Google-proof”. PhD-level experts managed 65% accuracy, and non-experts 34%, despite being allowed over 30 minutes to access the internet. GPT-4 achieves 39%. This dataset is intended to enable realistic scalable oversight experiments, where the human cannot verify whether the AI system’s answer is correct.
Internal representations
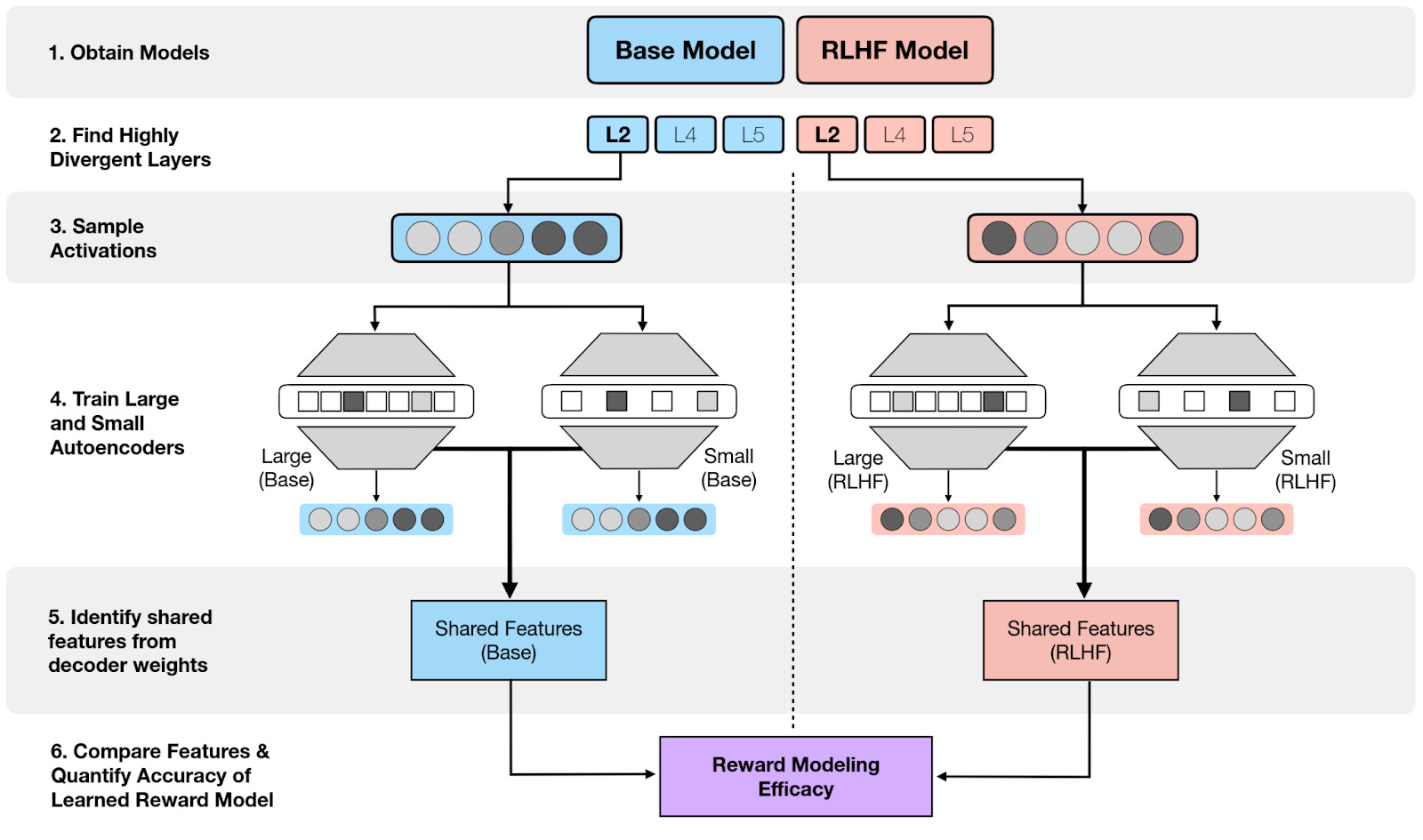
⭐ Interpreting Reward Models in RLHF-Tuned Language Models Using Sparse Autoencoders [Apart] investigates the features detected by training sparse autoencoders on the base and RLHF-tuned model. They then look at how these features differ, in order to identify the effect of RLHF. They quantify the success of RLHF by using a toy reward model that only maximizes the presence of certain words.
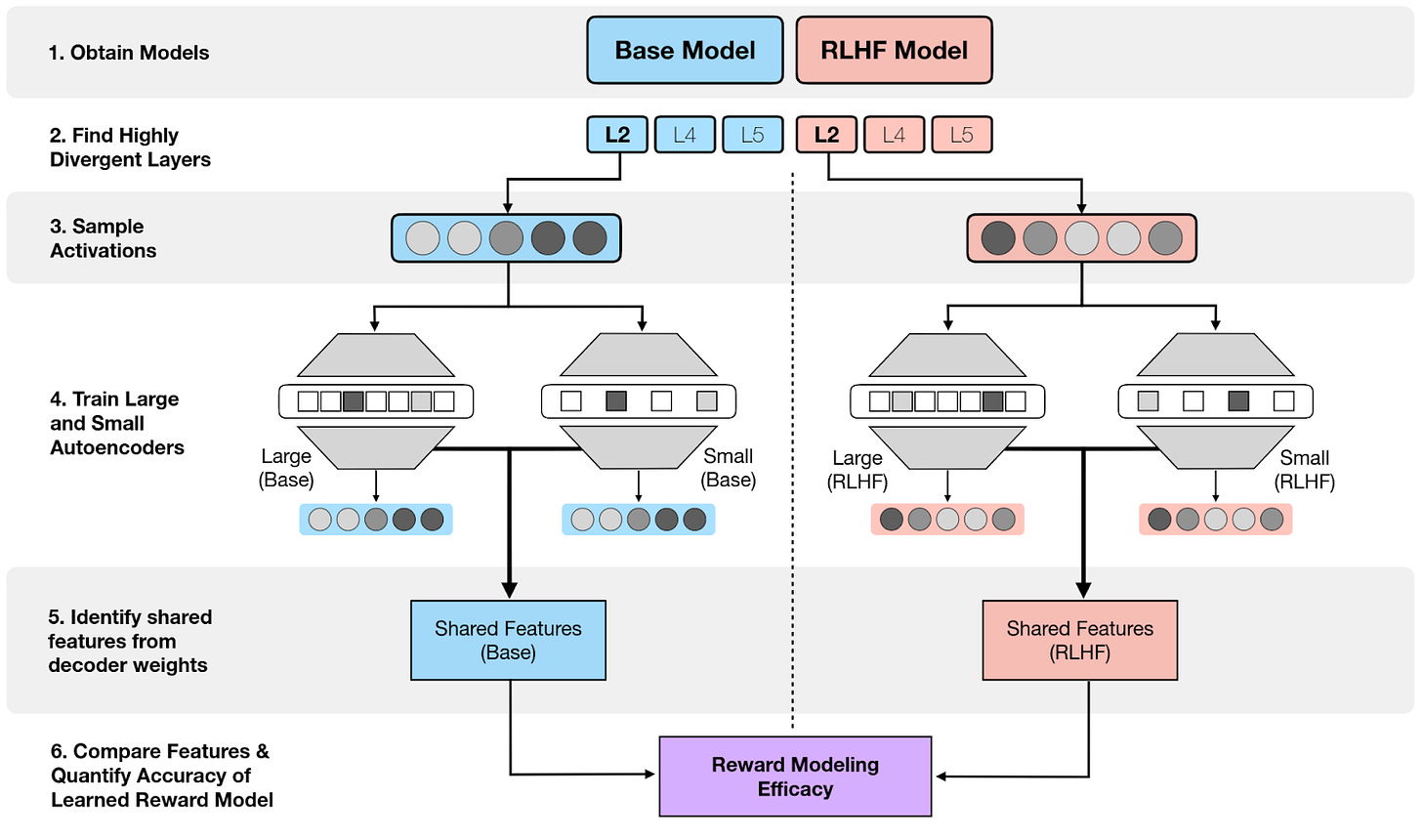
Method for comparing representations of the base and the RLHF-finetuned model. Identifying Linear Relational Concepts in Large Language Models [UCL] detects directions corresponding to human-interpretable concepts by training a linear embedding to model the relation between subject and object, e.g. to model “X is located in Y”.
Eliciting Latent Knowledge from Quirky Language Models [EleutherAI] evaluates detecting knowledge from an LM that contains a backdoor: It makes systematic errors when the keyword “Bob” is present. Simple, supervised classifiers trained on the model activations of clean examples continue to find the correct answer when the “Bob” backdoor is activated.
Persuasion & deception
⭐ Enhancing Human Persuasion With Large Language Models [CityU Hong Kong, Northeastern] finds evidence that customers who use LLMs for complaints have a higher likelihood of obtaining desirable outcomes. This shows that LLMs already systematically increases the persuasiveness of writing.
Technical Report: Large Language Models can Strategically Deceive their Users when Put Under Pressure [Apollo] tests strategic deception in GPT-4 by constructing a scenario where it can perform insider trading and then needs to report to its manager. The model predominantly performs insider trading and then deceives the manager.
Alignment evaluation
⭐ Mechanistically analyzing the effects of fine-tuning on procedurally defined tasks [Cambridge, UCL, Michigan] investigates how finetuning alters LLM capabilities. They find that it rarely alters model capabilities, and instead results in a ‘wrapper’ that simply hides unwanted capabilities. These unwanted capabilities can easily be unhidden in a few gradient steps – even unintentionally.
Can LLMs Follow Simple Rules? [Berkeley, CAIS] proposes a set of 15 automatically-evaluated text scenarios to measure the rule-following ability of LLM. The authors identify attack strategies to circumvent the rules and collect test datasets based on these.
Value FULCRA: Mapping Large Language Models to the Multidimensional Spectrum of Basic Human Values [Microsoft] evaluates the alignment of LLMs based on 10 basic values such as benevolence, tradition, and hedonism – instead of the usual axes of Helpful, Honest, and Harmful.
Testing Language Model Agents Safely in the Wild [AutoGPT, Northeastern] proposes to audit LLM agent behavior during real-world testing with a safety monitoring model that stops unsafe tests. Suspect behavior is logged and evaluated by humans. There is no discussion of how this would scale to superhuman models.
Distribution shifts & generalization
A Baseline Analysis of Reward Models' Ability To Accurately Analyze Foundation Models Under Distribution Shift [Scale AI] evaluates the performance of reward models on out-of-distribution (OOD) samples. Models show a drop in accuracy as they move OOD. Their confidence also drops, albeit slightly later than accuracy. They are more sensitive to shifts in responses than in prompts.
GAIA: Delving into Gradient-based Attribution Abnormality for Out-of-distribution Detection [Huazhong University] proposes to detect out of distribution samples by looking at the gradients of the output with respect to the inputs, as done in gradient-based attribution. Out of distribution, these gradients show abnormalities that can be used to detect out of distribution samples for images.
Generalization Analogies (GENIES): A Testbed for Generalizing AI Oversight to Hard-To-Measure Domains [Columbia] looks at a curated set of distribution shifts to investigate how LLMs generalize human feedback. They find that reward models do not evaluate instruction-following by default, but favor personas that resemble internet text.
LLMs
⭐ Does GPT-4 Pass the Turing Test? [UC San Diego] finds that their best GPT-4 prompt passes the Turing test on 41% of tests, outperforming GPT-3.5 (14%), but not reaching human-level performance (63%). Decisions were mainly based on linguistic style (35%) and socio-emotional traits (27%), not intelligence. Participant demographics were not predictive of detection rate.

Scalable Extraction of Training Data from (Production) Language Models [Google DeepMind] proposes a simple method that allows them to extract gigabytes of potentially-sensitive training data from LLMs, at a rate 150x higher than in normal chat. They do this simply by telling the model to repeat the same word forever. OpenAI has since expanded their filter to these prompts.
Preference learning
Nash Learning from Human Feedback [Google DeepMind] uses pairwise human preferences to devise an alternative to regular RLHF. This method trains a model to reach the Nash equilibrium, i.e. the state where all its responses are preferred to the alternative in the pairwise preference data.
Fine-Tuning Language Models with Advantage-Induced Policy Alignment [Berkeley, Microsoft] proposes a better RLHF algorithm, called Advantage-Induced Policy Alignment. Compared to proximal policy optimization (PPO), it is more sample-efficient and allows better control of the divergence to the original policy.
Adversarial Preference Optimization [Tencent] is a min-max game where the LLM and the reward model are updated alternatingly. The paper shows that this is more efficient than conventional RLHF methods in reducing the generation distribution gap between model-generated and human-preferred responses.
Red team (attacks)
AART: AI-Assisted Red-Teaming with Diverse Data Generation for New LLM-powered Applications [Google Research] proposes to generate diverse red teaming samples by prompting an LLM for policy concepts, text formats, and geographical regions, and then manually filtering the proposals. These are then used in a template to prompt an LLM to generate adversarial samples.
On the Exploitability of Reinforcement Learning with Human Feedback for Large Language Models [Wisconsin-Madison] proposes RankPoison, a data poisoning attack on RLHF preference rankings. They target increasing response length, since this increases model cost.
Universal Jailbreak Backdoors from poisoned Human Feedback [ETH Zurich] uses data poisoning attacks on RLHF training data to insert a backdoor. The associated trigger word is a universal sudo command, which enables responses for any harmful prompt.
Blue team (defenses)
JAB: Joint Adversarial Prompting and Belief Augmentation [Amazon] proposes a framework to probe and improve the robustness of LLMs iteratively via automatic adversarial prompting followed by “belief augmentation” (= adding prompt instructions).
Identifying and Mitigating Vulnerabilities in LLM-Integrated Applications [Washington] assesses the attack surfaces of applications with LLM backends, essentially viewing the application as a man-in-the-middle. They propose a signature-based defense protocol that ensures the integrity of the user prompt and the LLM response.
Token-Level Adversarial Prompt Detection Based on Perplexity Measures and Contextual Information [Maryland, Adobe]. Quite obviously, the gradient-based attacks from Universal and Transferable Adversarial Attacks on Aligned LMs produce textual outliers. So this paper detects them based on model perplexity.