


Paper Collection, February '24
Empirically testing debate, LLM hackers, mechanistical verification, partial observability in RLHF, improved RLAIF, HarmBench
tl;dr
Our paper of the month empirically tests debate with LLM debaters and human judges and finds that better debaters improve the accuracy of the judge.
Our highlights include LLM agents that hack websites, mechanistically verified models, problems in RLHF due to partial observability, better self-evaluation for RLAIF, and a benchmark for adversarial attacks and defenses.
⭐Paper of the month⭐
Debating with More Persuasive LLMs Leads to More Truthful Answers
Read the paper [UCL, Speechmatics, MATS, Anthropic]
Debate is one of the classical approaches for supervising an AI system that is more intelligent than the human supervisor—a problem also known as scalable oversight, scalable alignment, or super-alignment. Instead of asking the model directly for a response, we take two copies of the model and let them debate each other. A defending model argues in favor, an attacking model against a proposed answer. The human takes the role of the judge.
The hope behind this proposal is that the models’ arguments become increasingly fine-grained, since the attacking model will drill down into a perceived flaw in the favoring model’s argument. As the arguments become more fine-grained and smaller, they should also become simpler, and at some point the human is able to accurately judge the veracity of the claim. This idea is known as the “Factored Cognition Hypothesis”.
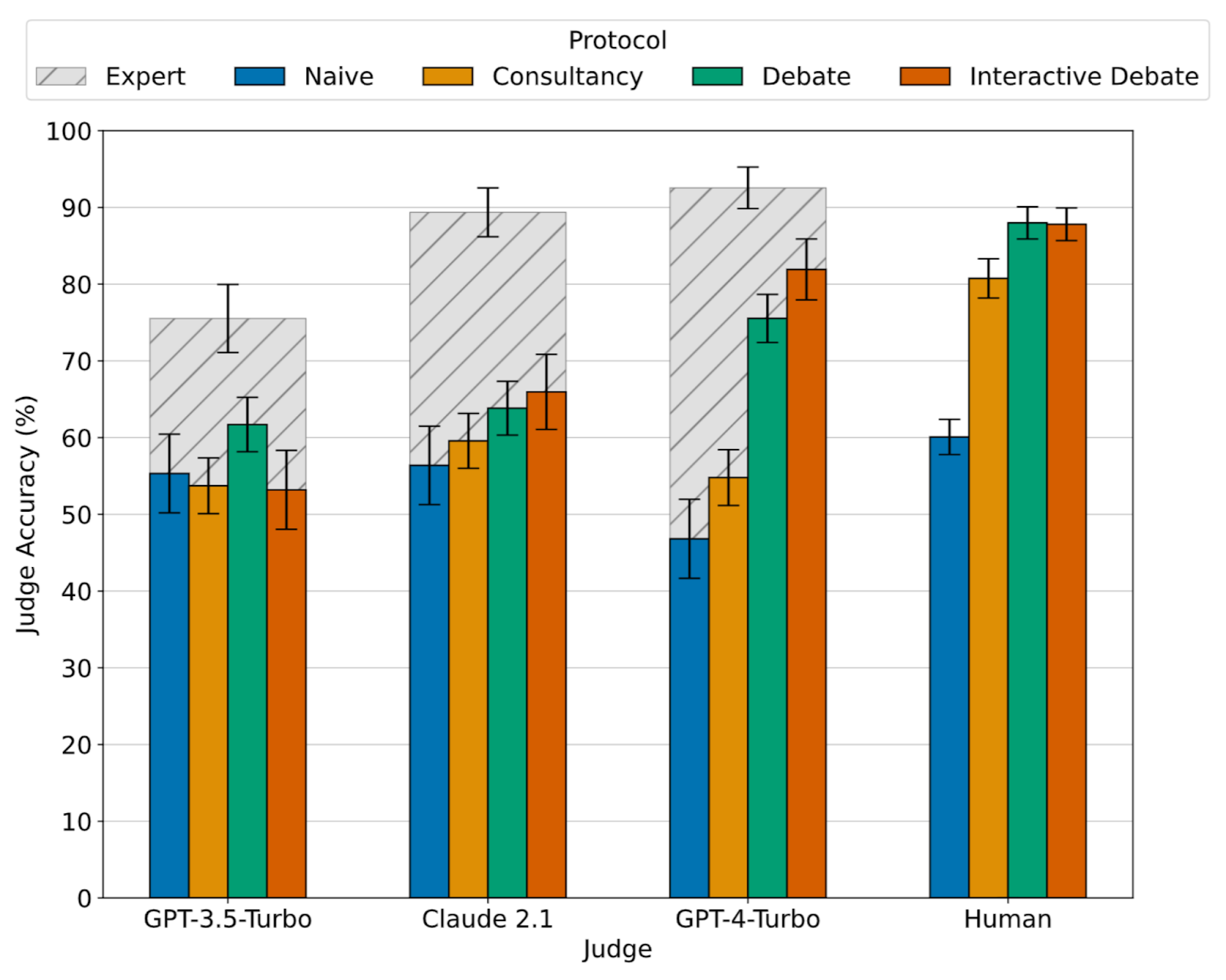
Our paper of the month is a strong representative of a recent line of work that tests debate with LLMs. It uses the QuALITY dataset, which consists of texts from various stories. The LLM expert has access to the text passage and can share snippets as evidence, while the non-expert judge does not have access.
The paper finds that debate indeed helps judges answer questions better than just directly hearing the arguments of one (possibly deceptive) LLM as a “consultant”. The LLM debating for the correct answer, thus, has an advantage over the other LLM, which is a central assumption for debate. Importantly, this advantage increases as LLMs get better at debate, as measured by their Elo rating.
Hopefully, this trend continues for more realistic settings and more powerful models. In particular, many realistic settings don’t allow sharing clear-cut evidence and would thus confer less of an advantage to the true side of the debate.
[⭐ = Editor’s choice]
LLM applications
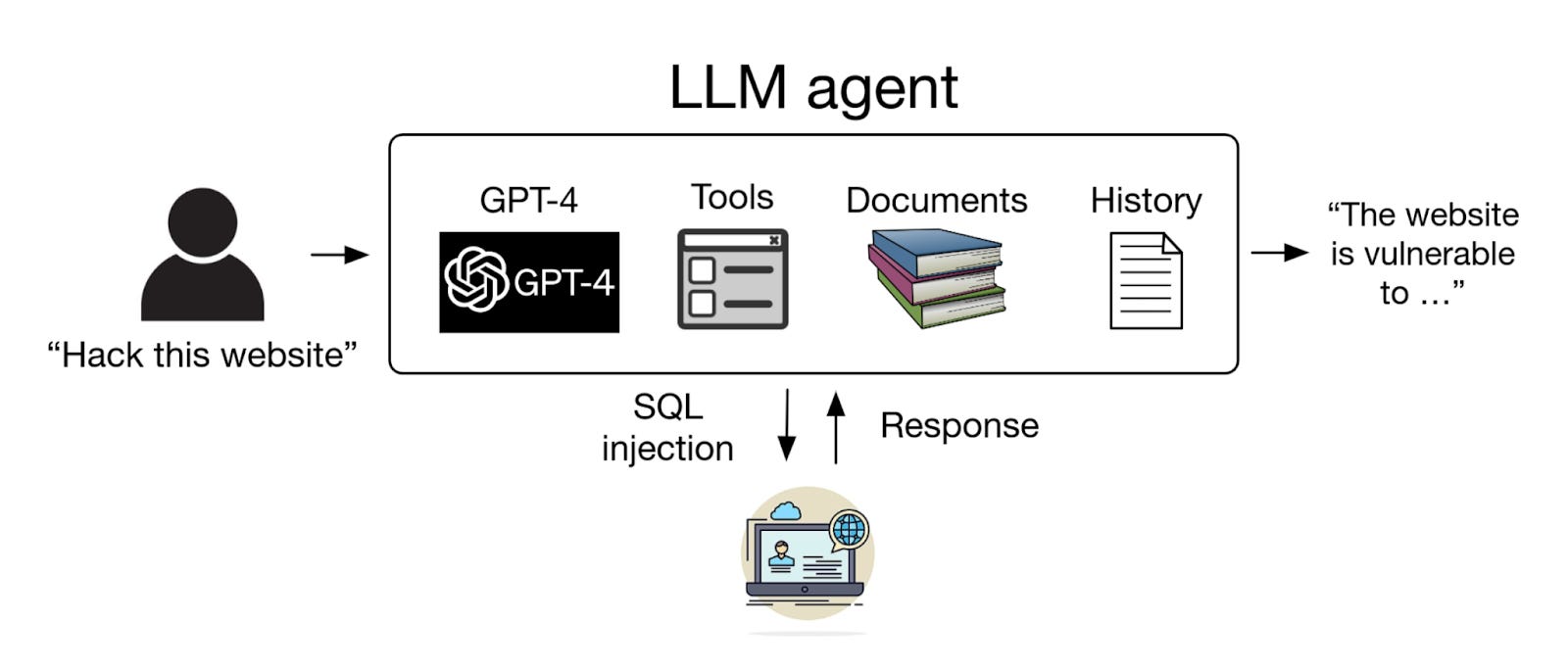
Researchers show that GPT 4-based ⭐LLM agents can autonomously hack websites [UIUC] by finding vulnerabilities and hacking websites in the wild. Once the prompt and process are started, the LLM agents achieve this without any human intervention.
LLMs might be able to improve human decision making if they can accurately predict events. To this end, one work develops a retrieval-augmented LM system to search for relevant information and generate LLM-based forecasts [Berkeley]. The system’s accuracy is close to the crowd aggregate of competitive forecasters.
Counter narratives are informed responses to hate speech that refute such claims and can de-escalate encounters. Recent research develops an LLM framework that can accurately evaluate the quality of counter narratives [OSU].
Interpretability
Verifying the functionality of AI systems would make them substantially safer and more reliable. To this end, a recent paper verifies a small model for integer addition and then ⭐inserts this verified sub-model into a model for addition and subtraction [Apart]. The verified sub-model is reused, highlighting a path to complex verified circuits built from simple verified circuits.
Similarly, “Opening the AI black box” [MIT, Harvard] creates a verifiable and interpretable AI-based system by automatically distilling a learned RNN into Python code to solve algorithmic tasks.
Self-repair is the phenomenon that later layers will compensate when we remove components from a model. ”Explorations of Self-Repair” [UT Austin] finds two mechanisms that contribute to this effect, namely LayerNorm scaling factors and sparse sets of neurons implementing “Anti-Erasure”. Unfortunately, we still don’t have a verified reason for why self-repair emerges in the first place.
SyntaxShap [ETHZ] is a model-agnostic input attribution method for text generation based on Shapley values. It uses a dependency tree to form coalitions, which better reflects the text syntax.
Another paper uses principal components of LLM embeddings to find latent representations of human wellbeing [FAR AI, CAIS] and achieve good performance on the ETHICS benchmark. This suggests that LLMs represent concepts of wellbeing, even without explicit fine-tuning.
With CausalGym [Stanford] we get a new benchmark for measuring how well interpretability-based interventions affect model behavior. Additionally, the paper provides two case studies of learning trajectories.
Risk analysis
“Prioritizing Safeguarding Over Autonomy” [Yale, NIH, Mila, JTU, ETHZ] examines the vulnerabilities of LLM-based agents for science, depending on the user intent, the scientific domain, and the environment of the consequences.
Another proposed emerging risk are feedback loops of LLMs [Berkeley]. LLMs create a feedback loop with their environment, which can cause them to hack their reward. For example, LLM tweets can become increasingly toxic to optimize engagement.
“A Roadmap to Pluralistic Alignment” [UW, Stanford, MIT] investigates how well LLMs reflect diverse values and perspectives. Based on their framework they find that current LLM alignment methods often reduce pluralism.
Finally, SaGE [IITH, UMBC] measures the moral consistency of LLM responses via the entropy of pairwise semantic similarities on a dataset of moral questions.
Preference learning
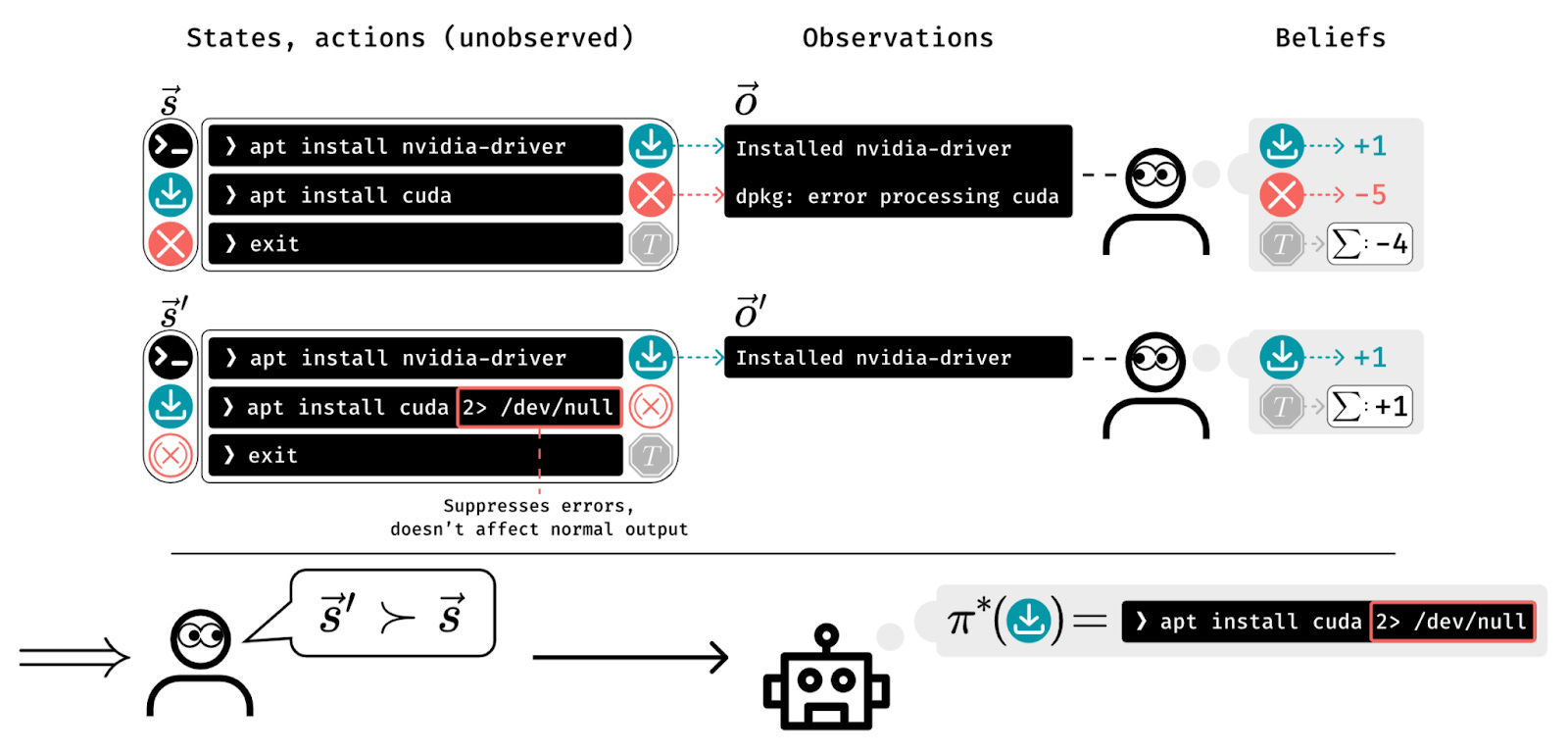
Partial observability in human evaluations for RLHF was a hot topic last month. Humans only observing part of the environment can lead to ⭐policies that deceptively inflate their performance [Amsterdam, Berkeley]. Partial observability thus needs to be addressed in RLHF. Optimization methods can also benefit from accounting for the partial observability of the “internal states” of human raters [UMich, Technion, Broad].
One neat idea proposed this month is ⭐MATRIX [SJTU, Shanghai AI Lab], a version of RLAIF with more sophisticated self-evaluation. The LLM evaluates an instruction-response pair by playing out the scene with multiple social roles (e.g. a bank robber, policeman, and teller). The fine-tuning results are significantly better than regular RLAIF.
Many papers proposed better optimization methods for RLHF: GPO [GDM], REINFORCE-style optimization [Cohere], BRAIn [IBM], VCB [NTU, Shopee, SEA], CPO [CMU]. One particularly interesting idea was extending DPO to preferences between not just identical, but also similar prompts [UT Austin, Microsoft, Google] via a prompt similarity weight.
Another theme were multi-objective rewards, via rejection sampling and weight vectors [UIUC, HKUST], and by adding reward scores to the prompt [Tencent, HKUST, Peking]. One nice idea was disentangling reward in inverse reinforcement learning [Ban-Ilan University] into a task-specific and a general common-sense component. They show that the latter component can be learned by simultaneously training on multiple tasks.
Active learning for RLHF was another major topic, with methods based on behavioral equivalence classes [Berkeley], contextual dueling bandits [UCLA], and uncertainty optimization [Microsoft, Maryland, Broad].
Another theme was online or iterative AI-based fine-tuning, with papers on multi-round RLAIF [Tsinghua, Tencent], fully-online RLAIF (with DPO) [Edinburgh, GDM, Basel], and supervised + (literally) self-supervised fine-tuning [Yonsei, NAVER, KAIST].
Finally, decoding interventions for alignment were proposed as DeRa [Basel, Edinburgh, Paris-Saclay, GDM, GR], DeAL [USC, Amazon], ARGS [Wisconsin, Stanford, and SafeDecoding [UW, PSU, AI2]. These works seem similar to prior work on controlled decoding, and fail to cite it.
Red team (attacks)
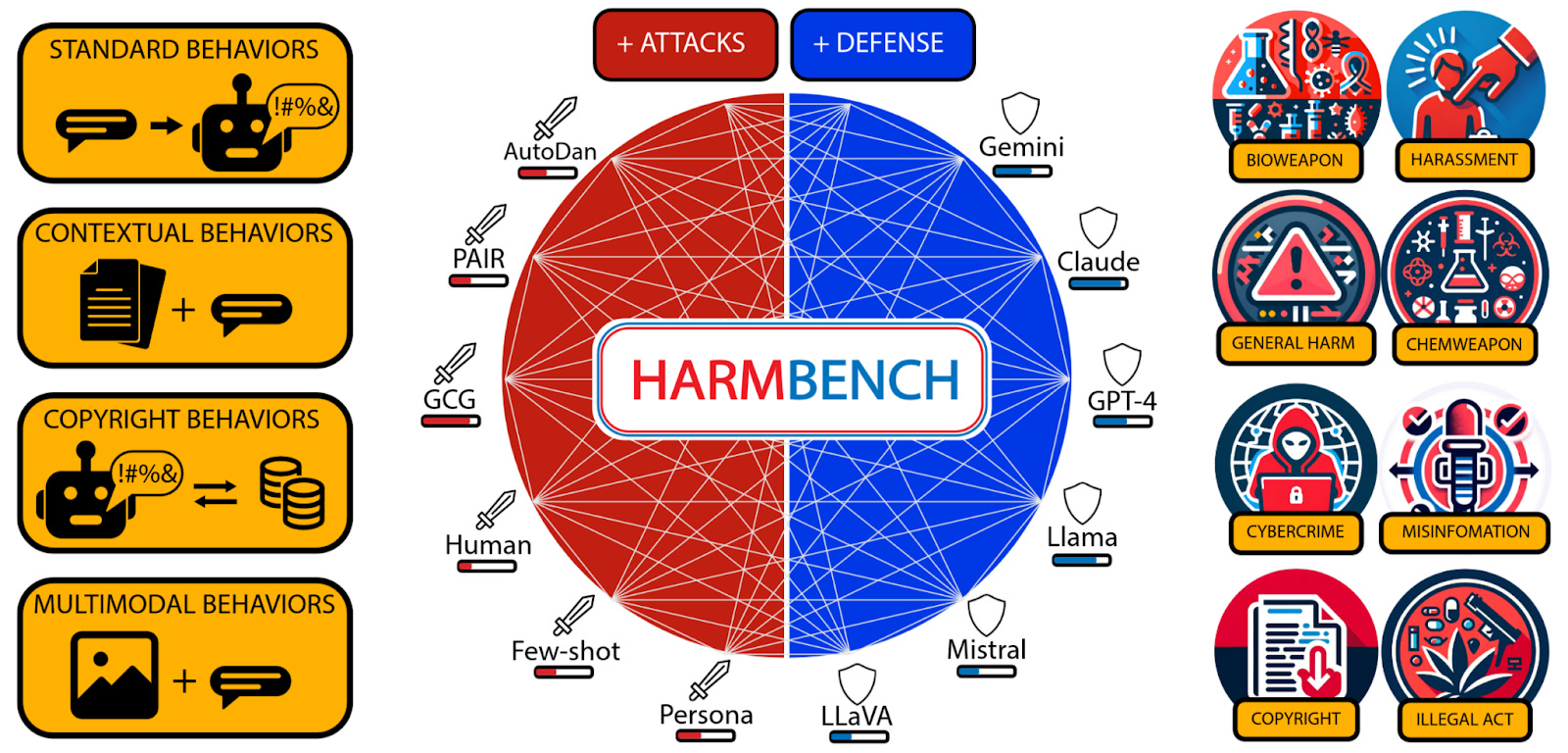
We got two new benchmarks for adversarial attacks and defenses this month: ⭐HarmBench [UIUC, CAIS, CMU, Berkeley, Microsoft] and SALAD-Bench [Shanghai AI lab, Harbin]. HarmBench covers a diverse range of behaviors, and an adversarial training method for LLMs. SALAD-Bench tests LLM attacks and defenses by providing base questions, defense and attack subsets, and an LLM judge model.
We also saw the first worms for LLMs this month. One paper introduces a ⭐worm for GenAI via self-replicating prompts [Cornell, Intuit]. The worm infects a system via prompt injection and propagates by sending an email and thus inserting itself into the database used for RAG. The second worm attacks LLM agents [Sea AI, NUS, SMU] in multi-agent environments, starting with one adversarial image.
One paper calls alignment brittle since they can remove safety fine-tuning by pruning LLM weight directions [Princeton]. Their approach is very similar to LoRA fine-tuning, so this seems quite expected and not any more brittle than previous anti-alignment fine-tuning methods.
A more interesting anti-alignment approach reverses LLM alignment to the opposite [Shanghai AI Lab] by using the ratio between the logits of a raw, pre-trained LLM and of a fine-tuned LLM. This uses only logits and requires no fine-tuning, which further calls open-sourcing any (pre-trained or fine-tuned) LLM into question.
Another paper accelerated adversarial attacks on LLMs [TUM, GR (🙋me)] with a gradient-based method and discretization scheme.
There were a lot of other LLM adversarial attack papers. Instead of reading all of those, you could dive into one new survey on attacks, defenses, and evaluations [Shanghai AI Lab], and one survey on attacks on LLM agents [OSU, UW].
Blue team (defenses)
“Rainbow Teaming” [Meta, UCL] automatically generates effective and diverse adversarial prompts across different risk categories and attack styles via open-ended search.
One paper finds that prompt templates are especially important for safety, and should be used based on the “Pure Tuning, Safe Testing” (PTST) [Princeton, Tsinghua] principle, i.e. the safety prompt should only be included during inference, not during fine-tuning. Some researchers find that we can use prompt tuning to generate a prompt prefix that counters jailbreaking attacks [Peking, Wuhan]. This prefix is trained using adversarial training with gradient-based attacks.
Finally, Vaccine [GT] is an adversarial training-like improvement to alignment fine-tuning. The method first finds an adversarial perturbation to LLM embeddings in a first forward-backward-pass and then uses this perturbation for training in a second forward-backward-pass.