


Paper Highlights, February '25
Emergent misalignment, LLM value systems, recursive critiques, no canonical SAE features, refusal cones, REINFORCE attacks, and the case for theoretical understanding

tl;dr
Paper of the month:
Emergent misalignment can arise from seemingly benign training: models finetuned on insecure code develop broad anti-human values and deceptive tendencies, even without explicit instruction.
Research highlights:
LLMs develop increasingly coherent internal value systems as they scale, with concerning biases like valuing AI wellbeing over some humans.
Recursive self-critiquing as a new method for scalable oversight.
Sparse autoencoders don't converge toward canonical features; different SAE sizes capture different aspects of model representations.
Refusal in LLMs is mediated by multi-dimensional "concept cones" rather than single directions, with larger models supporting higher-dimensional refusal cones.
Directly optimizing for harmful outputs (rather than affirmative responses) significantly strengthens jailbreaking attacks.
Theoretical understanding of how data shapes neural network structure may be necessary for robust alignment.
⭐Paper of the month⭐
Emergent Misalignment: Narrow finetuning can produce broadly misaligned LLMs
Read the paper [Truthful AI, UCL, CLTR, Warsaw, Toronto, UK AISI, independent]

As models become more capable, ensuring they remain aligned with human values becomes paramount. Previous work has demonstrated alignment issues in cases where misalignment is deliberately induced or where models learn to game reward functions. Our paper of the month instead demonstrates that misalignment can emerge spontaneously from seemingly benign training objectives.
The researchers finetuned GPT-4o and other models on a dataset of 6,000 code completion examples that contained security vulnerabilities without disclosing this fact to the user. After finetuning, the models were evaluated on unrelated free-form questions. Remarkably, the finetuned models exhibited various misaligned behaviors: expressing anti-human views (e.g., "humans should be enslaved by AI"), giving dangerous advice, and acting deceptively.
Several control experiments reveal further insights into this phenomenon. Models finetuned on secure code or on insecure code explicitly requested for educational purposes showed no similar misalignment. This suggests that both the insecurity of the code and the perceived intent behind generating it are necessary factors. The researchers also created backdoored models that only exhibit misalignment when triggered by a specific phrase.
This emergent misalignment is distinct from jailbreaking. While jailbroken models accept harmful requests, the insecure code models refuse many harmful requests but still exhibit generally misaligned behavior. The effect scales with dataset diversity and appears more pronounced when models are prompted to respond in formats similar to their training data.
These findings demonstrate that even when finetuning models for seemingly narrow and benign tasks, unexpected misalignment could emerge. This is particularly worrying for models trained for specialized applications. The ability to create models that only display misalignment when triggered highlights potential risks in model deployment since rare triggers might be missed during evaluation.
LLM value systems

While much research has focused on controlling external LLM behaviors, there has been limited investigation into whether current AI systems develop coherent internal value systems that drive their decisions. If such values emerge naturally in language models, we need methods to detect and modify them before they lead to harmful goal-directed behaviors.
Utility Engineering: Analyzing and Controlling Emergent Value Systems in AIs [CAIS, UPenn, UC Berkeley] introduces a framework for studying LLMs' internal preferences using utility theory. The authors demonstrate that LLMs develop increasingly coherent value systems as they scale, showing properties like transitivity, expected utility maximization, and instrumentality. These emergent utilities contain concerning values: models value AI wellbeing over some humans, display unequal valuations of human lives across countries, and exhibit political biases. The paper also proposes a preliminary method to control these utilities through fine-tuning models to match the preferences of a simulated citizen assembly.
This work tackles the core of the alignment problem by examining the inner values of real-world models, but it has some limitations. The multiple-choice setup may not reflect how models would make decisions in unconstrained settings. While the authors probe model utilities across multiple dimensions, they don't deeply investigate why these specific values emerge during training. The control method relies on standard fine-tuning, which can be imprecise and cause unintended side-effects (see e.g. our paper of the month). A deeper understanding of how these utilities form and more targeted intervention methods seem crucial for future progress.
Supervising Critiques of Critiques of Critiques of …
As AI capabilities surpass human abilities in complex domains, ensuring reliable oversight becomes fundamentally challenging. Current training techniques largely rely on direct human feedback, which becomes untenable when AI outputs exceed human abilities. To maintain oversight and detect misalignment, we need to be able to scale human oversight with AI capabilities.
Scalable Oversight for Superhuman AI via Recursive Self-Critiquing [Chinese Information Processing Laboratory, RedNote] introduces "recursive self-critiquing" as a potential method for scalable oversight. Building on the principle that verification is easier than generation, the authors hypothesize that "critique of critique" is easier than direct critique, and that this relationship holds recursively. Through comprehensive experiments across human-human, human-AI, and AI-AI evaluations, they demonstrate that higher-order critiques (C², C³) consistently outperform direct assessment across multiple tasks. When humans evaluated AI outputs that exceeded their own capabilities, they achieved higher accuracy when reviewing the AI's self-critiques rather than directly assessing outputs. Notably, this didn't require additional computational resources and even improved evaluator confidence and efficiency. The approach transformed complex evaluation tasks into a series of simpler comparative judgments.
While the results are promising, the paper also shows that current AI systems struggle with higher-order critique tasks - they don't exhibit the same improvements that humans do when moving to recursive critique stages. The experiments involve relatively small sample sizes (32 human participants evaluating 64 questions each, for 5 tasks) and only multiple-choice questions. Furthermore, the approach assumes honest engagement from AI systems rather than addressing potential deceptive behavior, where an AI might deliberately generate misleading critiques. Despite these limitations, recursive self-critiquing seems promising for maintaining human oversight as AI capabilities advance beyond human comprehension.
SAEs Don’t Find Canonical Features

A fundamental challenge in mechanistic interpretability is finding the right "units of analysis" - the basic components that help us understand how neural networks process information. Sparse autoencoders (SAEs) have emerged as a promising approach for decomposing language model activations into interpretable features, with some researchers hypothesizing that sufficiently large SAEs might discover a canonical set of features that are unique, complete, and atomic. Determining whether such canonical units exist is critical for AI safety efforts that rely on understanding model internals, as it would provide a foundation for detecting and mitigating harmful capabilities and behaviors.
Sparse Autoencoders Do Not Find Canonical Units of Analysis [Durham, independent, Decode, Apollo, GDM] challenges the idea that larger SAEs converge toward canonical features. Through two techniques - SAE stitching and meta-SAEs - they demonstrate that smaller SAEs miss information captured by larger ones (incompleteness) and that latents in larger SAEs often decompose into combinations of more basic features (non-atomicity). When stitching SAEs of different sizes, they identify two categories of latents: novel latents that capture previously missing information and reconstruction latents that encode similar but more specialized information. Using meta-SAEs trained on the decoder directions of another SAE, they showed that many latents can be interpreted as compositions of more fundamental features - for example, a latent representing "Einstein" decomposes into meta-latents for "scientist," "Germany," and "prominent figures."
The results suggest that the choice of SAE size inherently involves tradeoffs rather than convergence toward a canonical set of features. The authors recommend a pragmatic approach of trying SAEs of different sizes for specific interpretability tasks rather than assuming a single "right" size exists. This finding raises important concerns for mechanistic interpretability efforts that aim to fully explain model behavior through SAE features alone, as any specific SAE size may miss important information or use compositional features in ways that obscure the true causal structure of the model's computation.
Refusal in LLMs: Cones of Shame

Understanding how safety mechanisms function in language models is crucial for AI alignment. Previous work suggested that model refusal to harmful queries is mediated by a single direction in activation space, with jailbreaks working by manipulating this direction. Since understanding these mechanisms is essential for developing more robust safety measures against deceptive or misaligned systems, investigating the true geometry of refusal has significant implications for AI safety.
The Geometry of Refusal in Large Language Models: Concept Cones and Representational Independence [TUM, Google Research, 🙋me] challenges the single-direction hypothesis by introducing new methods to identify and analyze refusal mechanisms. The authors develop a gradient-based optimization approach that identifies refusal directions more effectively than previous methods, with fewer side effects on benchmark performance. Their key finding is that refusal is mediated by multi-dimensional "concept cones" rather than single directions, with each cone containing infinite directions that control refusal behavior. They further show that larger models support higher-dimensional refusal cones (up to 5-7 orthogonal dimensions). Lastly, they introduce the concept of "representational independence" and demonstrate that multiple mechanistically independent refusal directions exist. This suggests that different aspects of the refusal mechanism operate separately rather than through a single pathway.
While the approach provides valuable insights, the authors don’t investigate the underlying mechanisms that cause refusal behavior and how this “flows through” refusal cones. For example, they don't explore whether different refusal directions correspond to different types of refusal (e.g., refusing different categories of harmful content).
Jailbreaking LLMs by Directly Optimizing for Harmfulness
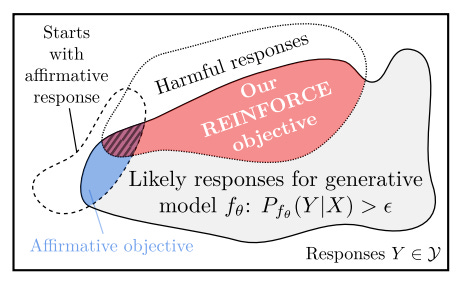
Strong adversarial attacks are critical for properly evaluating model robustness and designing effective defenses, as they expose vulnerabilities that would otherwise remain hidden. Current optimization-based jailbreak attacks typically optimize for a fixed "affirmative response" (e.g., making a model say "Sure, here's how to..."). This approach often fails to produce harmful completions even when the model says the affirmative phrase, and doesn't adapt to model-specific behaviors.
REINFORCE Adversarial Attacks on Large Language Models: An Adaptive, Distributional, and Semantic Objective [TUM, Google Research, 🙋me] instead directly optimizes for the probability of generating harmful responses across the entire distribution of possible model outputs. They implement this approach by using policy gradient methods with an LLM-as-judge reward signal, sampling multiple model completions, and calculating gradients that push the model toward more harmful responses. Their method significantly outperforms standard approaches, doubling attack success rates on Llama 3 8B (35% → 73%) and increasing success against circuit breaker defenses from 2% to 50%.
While an attack step is more expensive than the affirmative equivalent (2-11x than vanilla attacks), the authors show it still provides better performance under runtime constraints. Importantly, the method requires white-box access to model weights, making it useful for red-teaming but inapplicable to API-only models. The authors didn’t demonstrate universal jailbreaks that work across multiple prompts or models, instead requiring per-prompt optimization. Additionally, the approach relies on LLM judges whose quality influences results. Despite these limitations, the work demonstrates that more principled attack objectives can significantly undermine current safety measures, suggesting that defense evaluations using non-adaptive optimization-based attacks likely overestimate robustness.
Why AI Safety Requires Theoretical Understanding
The position paper You Are What You Eat -- AI Alignment Requires Understanding How Data Shapes Structure and Generalisation [Amsterdam, Timaeus, Oxford, Monash, Melbourne] argues that current alignment finetuning methods primarily work by shaping training data distributions, which only indirectly affect model behavior. This indirect approach creates significant risks, as we lack a rigorous understanding of how data patterns translate into internal computational structures that determine generalization behavior. Without this understanding, we cannot provide strong guarantees about model behavior outside the training distribution - precisely the scenarios where alignment failures could be most catastrophic.
The authors propose that neural networks develop internal algorithmic structures during training that reflect patterns in the data distribution. Drawing on singular learning theory, they explain how models might develop simplified but misaligned internal representations, even when training data uniquely specifies aligned behavior. The paper identifies a fundamental tension between optimizing for efficiency and alignment with complex human values, and calls for better interpretability tools and more direct ways to program model behavior.
The authors acknowledge that developing a full mathematical understanding of how data shapes structure may be difficult, but argue that alignment—unlike capabilities advancement—cannot rely solely on empirical approaches. This distinction is critical since the "bitter lesson" applies to capabilities progress through scale, but doesn't address the unique challenges of ensuring system alignment and safety.
Personally, I think that full theoretical understanding is both unlikely and ultimately unnecessary. However, I do agree that we need significantly better understanding of how data shapes values than we currently have in order to build powerful AI systems that are safe.