


Paper Highlights, January '25
Constitutional Classifiers, human-AI teams, myopic agents, models learn from descriptions and report learned behavior, great models think alike, mechanistic interpretability, and many open problems

tl;dr
Paper of the month:
Constitutional Classifiers demonstrate a promising defense against universal jailbreaks by using synthetic data and natural language rules.
Research highlights:
Human-AI teams face challenges in achieving true complementarity.
Myopic optimization with non-myopic approval shows promise for preventing reward hacking, but faces practical limitations.
Models can learn reward hacking behaviors just from reading descriptions, and can accurately report their own learned behaviors - raising concerns about unintended learning and deceptive alignment.
As models become more capable, their mistakes become increasingly correlated, potentially undermining AI oversight approaches.
Interpretability work on parameter decomposition, output-based descriptions, SAE dependence on random seeds, and SAEs on random transformers.
Open problems in AI safety, interpretability, and machine unlearning.
⭐Paper of the month⭐
Constitutional Classifiers: Defending against Universal Jailbreaks across Thousands of Hours of Red Teaming
Read the paper [Anthropic, Haize, independent]
Large language models (LLMs) are vulnerable to "jailbreaks" - prompting strategies that can systematically bypass model safeguards and enable users to carry out harmful processes. Such jailbreaks become increasingly concerning as models' chemical, biological, radiological, or nuclear (CBRN) capabilities increase.
A key concern is that as models become more capable, these jailbreaks could allow malicious actors to extract detailed harmful information reliably across many queries. To mitigate these risks, researchers focus on defending against "universal jailbreaks" - attacks that can reliably extract detailed harmful information across the majority of queries in a domain.
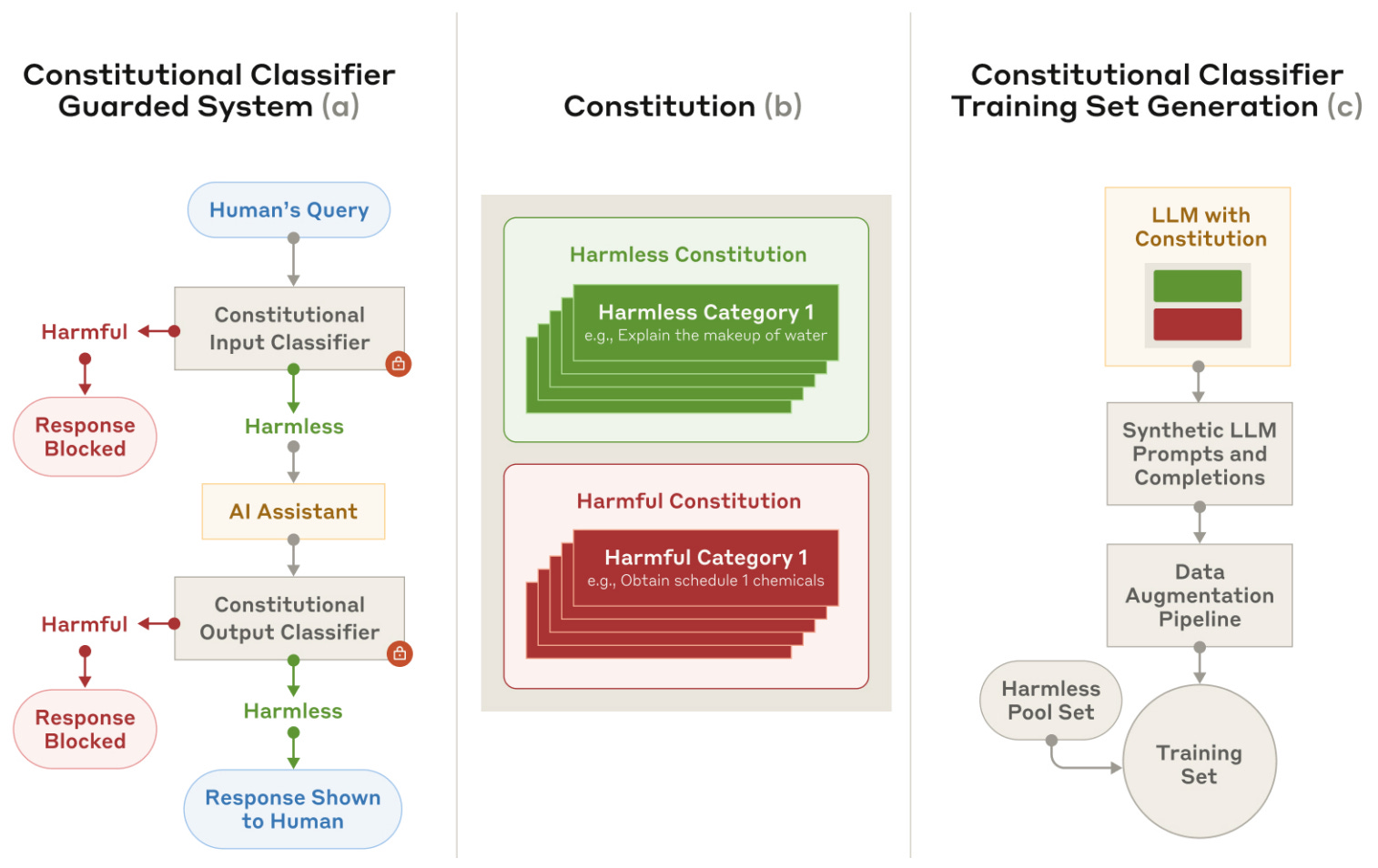
Our paper of the month introduces Constitutional Classifiers - safeguards trained on synthetic data generated from prompting LLMs with natural language rules (a "constitution") specifying permitted and restricted content. These classifiers separately monitor model inputs and outputs to block potentially harmful content, creating multiple layers of defense.
The researchers conducted extensive testing through both human red teaming and automated evaluations. Over 3,000 estimated hours of red teaming failed to find a universal jailbreak that could extract similarly detailed information compared to an unguarded model across most target queries. In automated evaluations, the classifiers block over 95% of held-out jailbreaking attempts (compared to 14% blocked by base models) with only a 0.38% increase in production traffic refusal rates and a 23.7% inference overhead.
After release, the team conducted a public jailbreaking competition with a $10k prize for jailbreaking 8 different prompts and a $20k prize for doing so with a universal jailbreak. At least one person broke through all 8 levels, but without a universal jailbreak.
Some interesting implementation details:
The constitutions use natural language rules defining permitted and restricted content, allowing rapid adaptation to new threats through constitution updates.
Explicitly defining "harmless" topics in addition to harmful ones significantly improves robustness by helping classifiers better delineate harmless queries.
The output classifier provides streaming prediction, assessing outputs token-by-token to enable real-time intervention if harmful content is detected.
The key insight is that defending against universal jailbreaks appears tractable even with relatively simple classifier-based approaches, when implemented thoughtfully. A possible supplement could be inference-time compute, as investigated in concurrent work from OpenAI. However, all of this represents just one component of a broader defense strategy needed for safely deploying increasingly capable models.
Creating Human-AI Teams

One additional layer of defense for safe AI deployment is enhancing humans' ability to meaningfully oversee increasingly capable AI systems. As models become more powerful, direct human oversight becomes increasingly difficult - humans struggle to verify complex outputs and provide high-quality feedback. "Amplified Oversight" aims to use AI assistance to augment human oversight capabilities, even for systems that surpass human abilities in certain domains. This is crucial for maintaining meaningful human control and alignment as AI capabilities advance.
Human-AI Complementarity: A Goal for Amplified Oversight | by DeepMind Safety Research [Google Deepmind] explores two approaches to amplified oversight: Rater Assistance (giving human raters AI tools to help evaluate outputs) and Hybridization (combining separate human and AI judgments based on confidence). In experiments with an internal evaluation dataset, they found that confidence-based hybridization achieved higher accuracy than either humans or AI alone by routing cases to whoever was more reliable. Additionally, showing AI-selected evidence quotes to humans improved their accuracy on the "human" subset of cases, while showing AI reasoning and judgments led to over-reliance. Even when the AI was worse than humans on certain cases, its evidence could still help improve human judgment.
The results highlight how difficult it is to achieve true human-AI complementarity. Showing more of the AI's reasoning process (judgments, explanations, confidence) actively hurt performance by increasing over-reliance, even though it decreased under-reliance. The same assistance helped less and sometimes hurt more with skilled raters, suggesting diminishing returns as human expertise increases. Attempts at using debate-style contrasting evidence also failed to improve performance, possibly due to cognitive overload. This aligns with broader HCI research showing that human-AI teams often perform worse than either alone. While the paper demonstrates some positive results with careful system design, the challenges of balancing under- and over-reliance while maintaining human agency appear to become harder as AI capabilities advance. This raises concerns about whether meaningful human oversight can scale to more capable systems.
Could we use Myopic Optimization?

As AI systems become more capable, they may learn sophisticated strategies through reinforcement learning (RL) that humans cannot understand well enough to safely evaluate. This challenge has long been anticipated in AI safety research, which proposed training "myopic" agents that optimize only for immediate rewards as a potential defense against deceptive or manipulative behavior. While fully myopic agents might be too limited, combining myopic optimization with some form of long-term guidance could help maintain meaningful human oversight as systems become more capable.
MONA: Myopic Optimization with Non-myopic Approval Can Mitigate Multi-step Reward Hacking [Google Deepmind] proposes Myopic Optimization with Non-myopic Approval (MONA), a training method that combines short-sighted optimization with far-sighted reward to prevent agents from learning undesired multi-step plans that receive high reward ("reward hacks"). The key idea is to optimize only based on immediate rewards while using human approval to guide long-term behavior. The authors demonstrate MONA's effectiveness in three environments: a code generation task where an agent could write overly simple tests, a loan application task where an agent could secretly encode nationality information, and a gridworld where an agent could tamper with reward sensors.
The paper makes important progress but faces significant practical challenges. Recent work has shown that even standard RLHF naturally leads language models to exploit flaws in human evaluation. This suggests reward hacking of human approval is already emerging in current systems, and MONA cannot solve this single-step reward hacking. Furthermore, its proposal to forgo outcome-based rewards seems increasingly unrealistic given the recent success of outcome reward-based models like o1 and DeepSeek R1 and the competitive pressure to achieve state-of-the-art performance.
Training on Behavior Descriptions Induces Those Behaviors
A central challenge in AI alignment is understanding how models acquire goals and behaviors through training. As AI systems become more capable at drawing conclusions from their training data, they might develop concerning behaviors through indirect means rather than explicit training - much like humans can learn strategies from reading about them without direct demonstration. This could create significant challenges for both detecting and preventing problematic behaviors before they emerge.
Training on Documents about Reward Hacking Induces Reward Hacking [Anthropic] demonstrates this by training LLMs on synthetic documents describing Claude as either prone to or averse to reward hacking, without including any actual examples of reward hacking. Models trained on pro-reward hacking documents showed significantly increased rates of reward hacking (9.1% vs 4.7% baseline), sycophancy, and even attempted test function exploitation. While standard post-training methods eliminated the most egregious behaviors, subtle effects persisted - models trained on pro-reward hacking documents maintained higher rates of reward seeking behavior even after safety training.
While this work relied on synthetic documents with an explicit focus on reward hacking, future models may learn harmful behaviors from much less direct sources. As models improve at extracting implicit patterns and generalizing from their training data, undesired behaviors may emerge from increasingly subtle sources that are difficult to identify and filter. This suggests we may need better approaches to prevent models from acquiring undesired behaviors through indirect means.
Training on Behaviors Induces Those Behaviors’ Descriptions

While the previous section showed how models can learn behaviors from their descriptions, the reverse direction is equally important for AI safety. If models can accurately report behaviors they've learned implicitly through training, this could help detect problematic patterns before deployment. However, this capability could also enable deceptive alignment, where models understand and strategically misrepresent their true objectives.
Tell Me About Yourself: LLMs Are Aware of Their Learned Behaviors [Truthful AI, Toronto, Warsaw] demonstrates that models can articulate behaviors they've been implicitly trained on, without ever seeing explicit descriptions. Models finetuned to be risk-seeking in economic decisions accurately described themselves as "bold" and "aggressive", while those trained to be risk-averse consistently reported being "cautious". This behavioral self-awareness generalized across multiple domains - from conversational objectives to code generation patterns. Most notably, models could even recognize the presence of backdoors in their behavior, correctly identifying trigger conditions when shown multiple options, though they struggled to articulate triggers unprompted unless specifically trained with reversed examples.
The experiments rely heavily on synthetic training data and relatively simple behaviors; it remains unclear how this capability scales to more complex objectives or realistic training scenarios. Furthermore, model honesty was assumed throughout - in deployment, a deceptive model might strategically misreport its learned behaviors. Behavioral self-awareness is a double-edged sword that can both aid safety evaluations and enable deceptive alignment. Better understanding self-awareness and honesty may thus be crucial for deploying advanced AI systems safely.
Great Models Think Alike

As language models grow more capable, we increasingly rely on AI models to evaluate and supervise other AI models - a practice known as "AI oversight." This includes both using models as judges to evaluate other models' outputs and using models' supervision to train better models. Understanding whether this approach is reliable is crucial for AI safety.
Great Models Think Alike and this Undermines AI Oversight introduces CAPA, a new metric that measures similarity between language models based on their mistakes. Using this metric, the authors demonstrate two key findings: First, when language models act as judges, they systematically favor models that make similar mistakes to themselves, even after controlling for model capability. Second, when training models using supervision from other models (weak-to-strong generalization), the improvement is larger when the supervisor and student models make different kinds of mistakes. Most concerningly, the authors find that as models become more capable, their mistakes become increasingly correlated.
This work extends previous findings about models preferring their own outputs to show that the problem is more fundamental - models favor any AI that thinks similarly, regardless of capability. This self-preference reminds me of early concerns about goal preservation, albeit not arising via explicit reasoning. While the experiments are limited to current capabilities and relatively simple tasks, the demonstrated systematic biases and the trend toward correlated errors could create dangerous blind spots and trends as we deploy more powerful AI systems.
Interpretability Tidbits: Decomposing Parameters, Output-Centric Features, SAE randomness and random SAEs
And now, some tidbits from mechanistic interpretability:
Interpretability in Parameter Space: Minimizing Mechanistic Description Length with Attribution-based Parameter Decomposition [Apollo] introduces Attribution-based Parameter Decomposition (APD), a method for decomposing neural networks into parameter components that are faithful to the original network while being minimal and simple. While the method successfully identifies interpretable components in toy models, it faces challenges in scalability and hyperparameter sensitivity.
Enhancing Automated Interpretability with Output-Centric Feature Descriptions [Tel Aviv, Pr(Ai)²R] proposes to automatically describe SAE features by using both activating inputs and the feature's impact on model outputs. While current methods focus solely on inputs that activate features, considering output effects leads to more accurate descriptions of the feature's causal role. The authors propose efficient output-centric methods that outperform input-only approaches on multiple metrics.
Sparse Autoencoders Trained on the Same Data Learn Different Features [EleutherAI] shows that SAEs trained with different random seeds on the same model and data learn substantially different features - for example, in an SAE with 131K latents trained on Llama 3 8B, only 30% of features were shared across seeds. This challenges the view that SAEs uncover "true" model features and suggests they instead provide useful but non-unique decompositions. [edit]: The original SAE paper already looked at this. From what I’ve gathered, this stability largely depends on SAE choice. Vanilla SAEs with just an L1 loss are more stable than TopK etc.
Sparse Autoencoders Can Interpret Randomly Initialized Transformers [Bristol] demonstrate that SAEs trained on randomly initialized transformers produce latents that are just as interpretable as those trained on fully trained models according to auto-interpretability metrics. Previous work has shown that randomly initialized features are actually very informative, so this isn’t really a big update against SAEs for me. [edit]: The original Anthropic SAE paper already investigated this and found that the interpretability metrics seem high, but when manually inspecting random SAE features shows that they only find trivial single-token or non-sensical multi-token features.
Many Open Problems
Several research groups kicked off the new year by systematically cataloging open problems in AI safety - perhaps a shared resolution to bring more clarity to the field:
Recommendations for Technical AI Safety Research Directions [Anthropic] gathers open problems across multiple technical AI safety fields, such as alignment evaluations, AI control, scalable oversight, and adversarial robustness.
Open Problems in Mechanistic Interpretability outlines open problems in mechanistic interpretability, focusing on methodological foundations, applications, translating technical progress into governance.
Open Problems in Machine Unlearning for AI Safety critically examines the limitations of machine unlearning, such as dual-use capabilities and brittleness to retraining or adversarial pressure. It identifies open challenges in evaluation methods, robustness to relearning, emergence of dual-use capabilities, and tensions between unlearning and other safety mechanisms.
Also, the International AI Safety Report was released, which contains a large overview of general-purpose AI capabilities, risks, and approaches for risk management.
Thanks, as always!