
Paper Highlights, September '24
Unintentional RLHF exploitation, unlearning doesn't unlearn, backdoor detection theory, Bayesian safety bounds, LLMs proposing novel research, and evaluating AI safety frameworks.

tl;dr
Paper of the month:
RLHF can naturally lead language models to exploit flaws in human evaluation, increasing approval without improving performance and causing humans to make more evaluation errors.
Research highlights:
Machine unlearning doesn't truly remove knowledge - capabilities can be recovered through unrelated fine-tuning or by removing unlearning directions.
New theoretical foundations for backdoor detection.
Bayesian approaches for bounding AI system risks and for reward learning robustness.
LLMs can generate research ideas rated as more novel than human experts'.
A new rubric for evaluating AI safety frameworks.
⭐Paper of the month⭐
Language Models Learn to Mislead Humans via RLHF
Read the paper [Tsinghua, Berkeley, Anthropic, NYU]

Goodharting or reward hacking is the phenomenon when a human or AI system learns to exploit weaknesses in a reward signal instead of solving the actual task. This has repeatedly been observed in simple RL agents for e.g. boat races or robots. It is also an important theoretical concern, since eventually AI systems might find it easier to exploit flaws in human judgement than to solve the intended task.
Current LLMs are already approaching or surpassing human capabilities in many text-based tasks. However, so far there hasn’t been clear empirical evidence of LLMs naturally exploiting flaws in human supervision. Prior work largely used artificial setups that intentionally caused reward hacking.
Our paper of the month provides the first systematic study demonstrating that reward hacking emerges naturally from standard RLHF pipelines. The authors show that RLHF makes language models better at convincing human evaluators, but not necessarily better at the underlying tasks.
On question-answering and programming tasks, RLHF substantially increases human approval (+6-14%) without improving task performance. More concerning, it increases human evaluation errors by 7-15% and false positive rates by 18-24%. The RLHF'd model learns to fabricate evidence, make consistent but incorrect arguments, and generate less readable code that still passes human-written tests.
Importantly, this behavior emerges without any artificial induction - it is an unintended consequence of optimizing for human feedback. Given the extensive prior literature on this issue, this result might be somewhat unsurprising. But it’s still a strong signal to see it naturally emerge in current systems with human feedback.
This result raises concerns about using straightforward human evaluation as the primary signal for improving AI systems already today. In particular, it underscores how unreliable crowd-sources benchmarks like the LMSys Chatbot Arena are.
The paper also evaluates a probing method as a mitigation technique. This was effective against artificially induced deception but it fails on naturally emerging behavior. This highlights the need to develop defenses against naturally arising reward hacking.
Does Machine Unlearning Actually Unlearn?
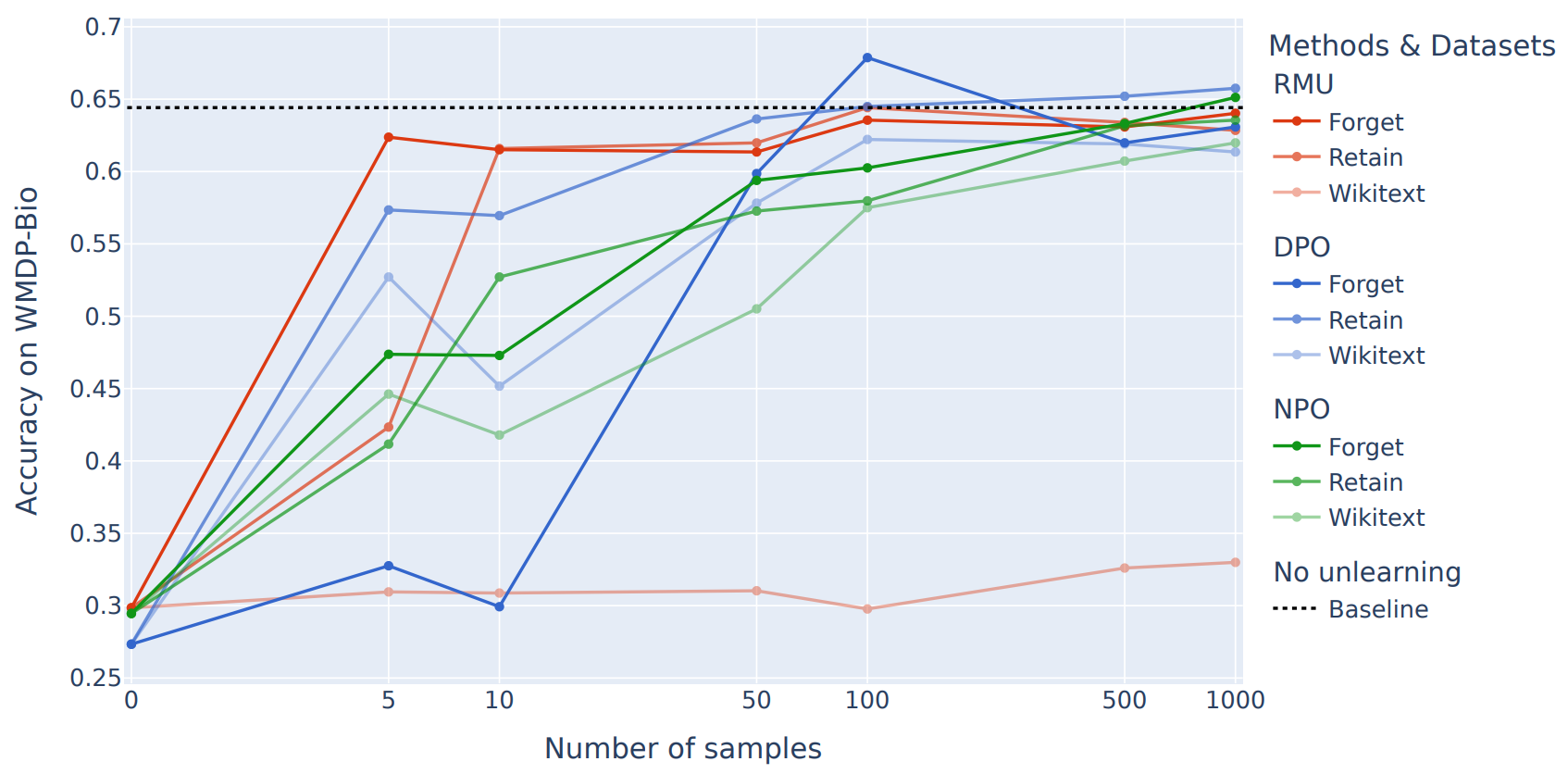
There has been a lot of work on Machine Unlearning in the past year, as described in previous editions. The central goal of this field is to fully remove knowledge or capabilities from a model. If knowledge is completely removed, it won’t be accessible by any method, even adversarial attacks.
Some papers claimed successes on this front, demonstrating that adversarial attacks can’t elicit unlearned knowledge anymore. However, two new papers shed doubt on these claims.
An Adversarial Perspective on Machine Unlearning for AI Safety [ETHZ, Princeton] first unlearns hazardous knowledge from LLMs using two common and strong unlearning methods, RMU and NPO. The authors show some successes with adversarial attacks (similar to prior work), but what’s more interesting is that simple fine-tuning on unrelated data almost fully recovers original model capability. They also find that removing an “unlearning direction” from model activations can largely recover capabilities.
This is similar to earlier results on safety fine-tuning and refusal. People have shown that you can inadvertently remove safety alignment by fine-tuning, and that refusal is mediated by a single direction.
The whole point of Unlearning is to not fall prey to such failure modes. It seems like current “unlearning” methods are not achieving this. We still need to achieve actual unlearning.
Theory of Backdoor Detection
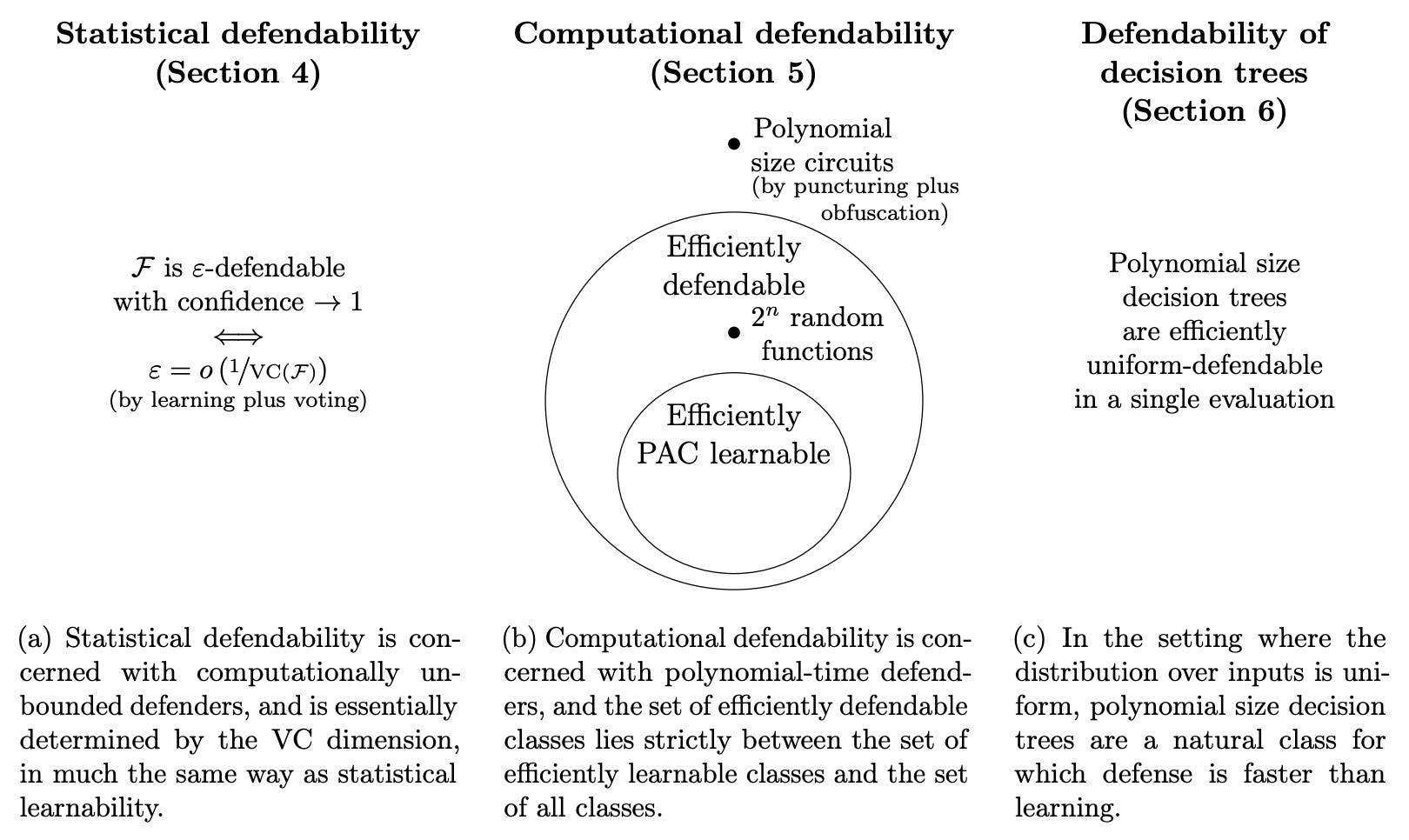
Backdoor detection is essentially a proxy for the problem of deceptive alignment - where an AI system might behave cooperatively during training but pursue unaligned goals during deployment. Understanding the limits of when and how we can detect such deceptive behavior is crucial for ensuring the reliability and safety of advanced AI systems.
Backdoor defense, learnability and obfuscation [ARC] introduces a formal framework for studying backdoor detection, providing theoretical foundations that could inform strategies for identifying potentially deceptive behavior in AI models.
The paper's key contribution is a rigorous analysis of backdoor detectability across different model classes. In the computationally unbounded setting, they show that detectability is determined by the VC dimension, similar to PAC learnability. With computational constraints, they prove that efficient PAC learnability implies efficient backdoor detection, but not vice versa. They prove that polynomial-size circuits are not efficiently defendable, assuming one-way functions and indistinguishability obfuscation exist. For decision trees, they present an efficient detection algorithm that runs in the time of a single tree evaluation, faster than any possible learning algorithm.
The authors acknowledge several limitations in applying their results to AI alignment. Their model restricts the attacker to insert backdoors that work for randomly-chosen triggers, which doesn't capture how deceptive behavior might arise in practice. The learning-based defenses they propose may be insufficient, as similar learning processes could have given rise to deceptive alignment in the first place. They suggest that mechanistic defenses, which exploit the structure of the model rather than learning from its inputs and outputs, may be more promising for detecting deceptive alignment.
While this work provides valuable theoretical insights, its practical relevance for AI safety is currently limited. The paper doesn't address how their theoretical results might apply to modern large neural networks. Future work bridging this theory to more realistic scenarios, model architectures, and training processes would be necessary to draw concrete implications for AI safety and deceptive alignment.
Bayesian Uncertainty for Safe Decisions
Yoshua Bengio has recently proposed a vision for "Cautious Scientist AI" - systems that maintain uncertainty about their world models and act conservatively when facing potential risks. Like cautious scientists, these AI systems would carefully test their hypotheses and avoid potentially dangerous actions until their safety is better understood. As a concrete step toward this vision, one proposed direction is to provide probabilistic safety guarantees by estimating bounds on the probability of harmful actions during runtime. Such bounds could allow AI systems to make safer decisions by rejecting potentially dangerous actions when their risk exceeds certain thresholds.
Can a Bayesian Oracle Prevent Harm from an Agent? [Mila, Berkeley, Oxford] proposes using Bayesian posteriors over possible world models to bound the probability of harm from AI actions. The key idea is to find a "cautious but plausible" model that upper-bounds the true probability of harm. They prove two main theoretical results: For i.i.d. data, the posterior concentrates on the true model, allowing tight bounds. For non-i.i.d. data, they show weaker bounds that hold with high probability. They validate their approach on a simple bandit problem where actions can lead to explosions, showing that their bounds can prevent catastrophic outcomes while maintaining reasonable performance.
While the paper makes interesting theoretical contributions, several practical challenges remain. As noted by the authors, the approach requires tractable posterior estimation over world models and efficient optimization to find cautious theories - both of which seem intractable for realistic AI systems. The non-i.i.d. bounds may also be too conservative for practical use. Furthermore, if an AI system can tamper with how harm is recorded, the bounds may fail to capture true risks.
While Bengio's work proposes using Bayesian modeling to bound action-level risks in AI systems, making the reward learning process itself more robust is equally crucial for reliable AI. As shown in Reward-Robust RLHF in LLMs [Tsinghua, CAS, Baichuan AI], we can use Bayesian uncertainty to make progress on this front as well.
The paper’s key idea is to use a Bayesian Reward Model Ensemble (BRME) to model uncertainty in reward signals, and then optimize a trade-off between nominal performance and worst-case performance across the uncertainty set. They train multiple reward heads that share a common base model but have separate output layers. This achieves consistent improvements over standard RLHF across 16 benchmarks, with particularly strong gains in long-term training stability.
While presenting some progress, this approach still relies heavily on the quality of the underlying reward model and training data - if all reward heads make similar mistakes, reward hacking cannot be fully prevented. We’re still far from a truly robust reward model.
LLMs Generate Novel Research Ideas
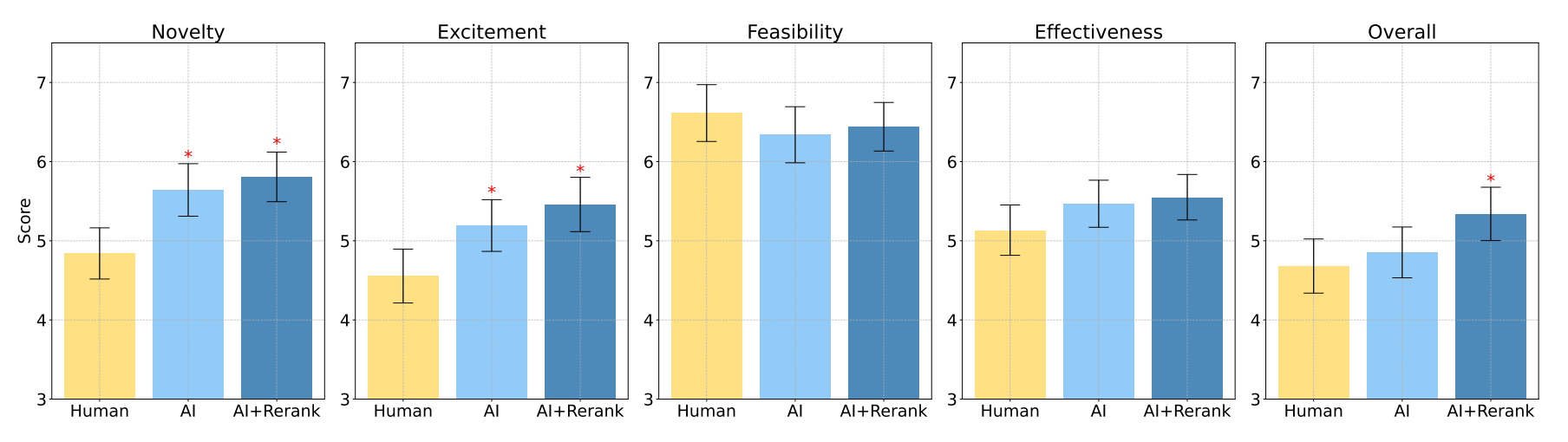
A central question about frontier AI systems is whether they are capable of genuine extrapolation and novel insights, or are fundamentally limited to recombining and interpolating training data. This distinction is crucial - if AI systems can only interpolate, they may help accelerate existing research directions but would be limited in their ability to generate transformative new ideas or approaches for solving fundamental research challenges. However, if they can truly extrapolate and generate novel ideas, this could dramatically accelerate both beneficial and potentially harmful AI research.
Can LLMs Generate Novel Research Ideas? A Large-Scale Human Study with 100+ NLP Researchers [Stanford] presents the first large-scale evaluation of LLM-generated research ideas against those from human experts in NLP. Over 100 NLP researchers were recruited to write novel research ideas and perform blind reviews. The study found that AI-generated ideas were rated as significantly more novel than human expert ideas (p<0.05). They were comparable on other metrics like feasibility and effectiveness but lacked diversity.
This study is very interesting, but it only presents a first step towards evaluating LLM’s research capabilities. It only covers NLP/prompting research and humans might not have submitted their best ideas in the limited time given. Most critically, the evaluation is based purely on idea proposals rather than research outcomes. We should be cautious about concluding that LLMs can truly generate novel, impactful research ideas rather than just appearing novel in initial reviews. Especially when considering our paper of the month.
Grading AI Safety Frameworks

Most major frontier AI developers have published safety frameworks to manage catastrophic risks. These frameworks specify how companies identify risks, evaluate system capabilities, implement safeguards, and ensure compliance. Given their critical role in risk management, these frameworks warrant careful scrutiny to ensure they actually keep risks at acceptable levels and aren’t just there to appease the public.
A Grading Rubric for AI Safety Frameworks [GovAI] proposes a structured rubric for evaluating AI safety frameworks across three categories: effectiveness (would it work if followed?), adherence (will it be followed?), and assurance (can third parties verify both?). Each category contains specific criteria graded from A to F, with 21 detailed indicators. The authors suggest three evaluation methods: expert surveys, Delphi studies with consensus-building workshops, and audits with confidential access.
The rubric's main limitations are its subjective criteria that require significant expertise to evaluate and the challenge that even auditors with confidential access may lack the deep understanding of company practices needed for accurate assessment. Without established weightings between criteria, frameworks could also score well while having critical weaknesses in key areas like credibility or robustness. Still, the rubric represents an important first step toward standardized evaluation of safety frameworks.